Probability distributions are fundamental concepts in statistics that describe how data is spread out or distributed. Understanding these distributions is crucial for students in fields ranging from social sciences to engineering. This essay will explore several key types of distributions and their characteristics.
Normal Distribution
The normal distribution, also known as the Gaussian distribution, is one of the most important probability distributions in statistics[1]. It is characterized by its distinctive bell-shaped curve and is symmetrical about the mean. The normal distribution has several key properties:
- The mean, median, and mode are all equal.
- Approximately 68% of the data falls within one standard deviation of the mean.
- About 95% of the data falls within two standard deviations of the mean.
- Roughly 99.7% of the data falls within three standard deviations of the mean.
The normal distribution is widely used in natural and social sciences due to its ability to model many real-world phenomena.
Skewness
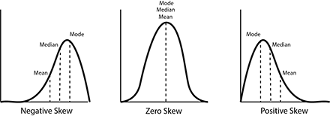
Skewness is a measure of the asymmetry of a probability distribution. It indicates whether the data is skewed to the left or right of the mean[6]. There are three types of skewness:
- Positive skew: The tail of the distribution extends further to the right.
- Negative skew: The tail of the distribution extends further to the left.
- Zero skew: The distribution is symmetrical (like the normal distribution).
Understanding skewness is important for students as it helps in interpreting data and choosing appropriate statistical methods.
Kurtosis
Kurtosis measures the “tailedness” of a probability distribution. It describes the shape of a distribution’s tails in relation to its overall shape. There are three main types of kurtosis:
- Mesokurtic: Normal level of kurtosis (e.g., normal distribution).
- Leptokurtic: Higher, sharper peak with heavier tails.
- Platykurtic: Lower, flatter peak with lighter tails.
Kurtosis is particularly useful for students analyzing financial data or studying risk management[6].
Bimodal Distribution
A bimodal distribution is characterized by two distinct peaks or modes. This type of distribution can occur when:
- The data comes from two different populations.
- There are two distinct subgroups within a single population.
Bimodal distributions are often encountered in fields such as biology, sociology, and marketing. Students should be aware that the presence of bimodality may indicate the need for further investigation into underlying factors causing the two peaks[8].
Multimodal Distribution
Multimodal distributions have more than two peaks or modes. These distributions can arise from:
- Data collected from multiple distinct populations.
- Complex systems with multiple interacting factors.
Multimodal distributions are common in fields such as ecology, genetics, and social sciences. Students should recognize that multimodality often suggests the presence of multiple subgroups or processes within the data.
In conclusion, understanding various probability distributions is essential for students across many disciplines. By grasping concepts such as normal distribution, skewness, kurtosis, and multi-modal distributions, students can better analyze and interpret data in their respective fields of study. As they progress in their academic and professional careers, this knowledge will prove invaluable in making informed decisions based on statistical analysis.