Bivariate analysis is a statistical technique used to examine the relationship between two variables. This type of analysis is often used in fields such as psychology, economics, and sociology to study the relationship between two variables and determine if there is a significant relationship between them.
Correlation
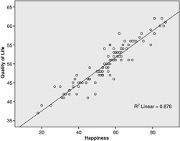
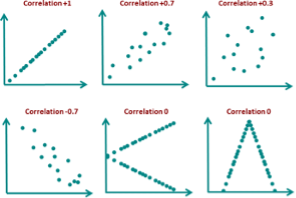
Correlation is a measure of the strength and direction of the relationship between two variables. A positive correlation means that as one variable increases, the other variable also increases, and vice versa. A negative correlation means that as one variable increases, the other decreases. The strength of the correlation is indicated by a correlation coefficient, which ranges from -1 to +1. A coefficient of -1 indicates a perfect negative correlation, +1 indicates a perfect positive correlation, and 0 indicates no correlation.
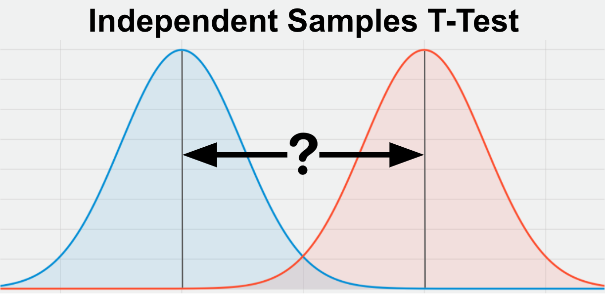
T-Test
A t-test is a statistical test that compares the means of two groups to determine if there is a significant difference between them. The t-test is commonly used to test the hypothesis that the means of two populations are equal. If the t-statistic is greater than the critical value, then the difference between the means is considered significant.
Chi Square Test
The chi square test is a statistical test used to determine if there is a significant association between two categorical variables. The test measures the difference between the observed frequencies and the expected frequencies in a contingency table. If the calculated chi square statistic is greater than the critical value, then the association between the two variables is considered significant.
Significance
Significance in statistical analysis refers to the likelihood that an observed relationship between two variables is not due to chance. In other words, it measures the probability that the relationship is real and not just a random occurrence. In statistical analysis, a relationship is considered significant if the p-value is less than a set alpha level, usually 0.05.
In conclusion, bivariate analysis is an important tool for understanding the relationship between two variables. Correlation, t-test, and chi square test are three commonly used methods for bivariate analysis, each with its own strengths and weaknesses. It is important to understand the underlying assumptions and limitations of each method and to choose the appropriate test based on the research question and the type of data being analyzed