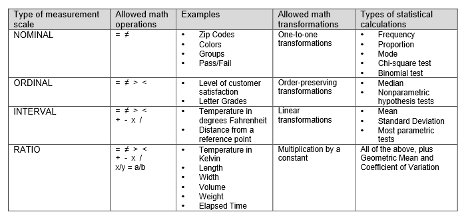
What is a great survey?
A great online survey provides you with clear, reliable, actionable insight to inform your decision-making. Great surveys have higher response rates, higher quality data and are easy to fill out.
Follow these 10 tips to create great surveys, improve the response rate of your survey, and improve the quality of the data you gather.
10 steps to create a great survey
1. Clearly define the purpose of your online survey
For BUAS we use Qualtrics which is a web–based online survey tool packed with industry–leading features designed by noted market researchers.
Fuzzy goals lead to fuzzy results, and the last thing you want to end up with is a set of results that provide no real decision–enhancing value. Good surveys have focused objectives that are easily understood. Spend time up front to identify, in writing:
- What is the goal of this survey?
- Why are you creating this survey?
- What do you hope to accomplish with this survey?
- How will you use the data you are collecting?
- What decisions do you hope to impact with the results of this survey? (This will later help you identify what data you need to collect in order to make these decisions.)
Sounds obvious, but we have seen plenty of surveys where a few minutes of planning could have made the difference between receiving quality responses (responses that are useful as inputs to decisions) or un–interpretable data.
Consider the case of the software firm that wanted to find out what new functionality was most important to customers. The survey asked ‘How can we improve our product?’ The resulting answers ranged from ‘Make it easier’ to ‘Add an update button on the recruiting page.’ While interesting information, this data is not really helpful for the product manager who wanted to make an itemized list for the development team, with customer input as a prioritization variable.
Spending time identifying the objective might have helped the survey creators determine:
- Are we trying to understand our customers’ perception of our software in order to identify areas of improvement (e.g. hard to use, time consuming, unreliable)?
- Are we trying to understand the value of specific enhancements? They would have been better off asking customers to please rank from 1 – 5 the importance of adding X new functionality.
Advance planning helps ensure that the survey asks the right questions to meet the objective and generate useful data.
2. Keep the survey short and focused
Short and focused helps with both quality and quantity of response. It is generally better to focus on a single objective than try to create a master survey that covers multiple objectives.
Shorter surveys generally have higher response rates and lower abandonment among survey respondents. It’s human nature to want things to be quick and easy – once a survey taker loses interest they simply abandon the task – leaving you to determine how to interpret that partial data set (or whether to use it all).
Make sure each of your questions is focused on helping to meet your stated objective. Don’t toss in ‘nice to have’ questions that don’t directly provide data to help you meet your objectives.
To be certain that the survey is short; time a few people taking the survey. SurveyMonkey research (along with Gallup and others) has shown that the survey should take 5 minutes or less to complete. 6 – 10 minutes is acceptable but we see significant abandonment rates occurring after 11 minutes.
3. Keep the questions simple
Make sure your questions get to the point and avoid the use of jargon. We on the SurveyMonkey team have often received surveys with questions along the lines of: “When was the last time you used our RGS?” (What’s RGS?) Don’t assume that your survey takers are as comfortable with your acronyms as you are.
Try to make your questions as specific and direct as possible. Compare: What has your experience been working with our HR team? To: How satisfied are you with the response time of our HR team?
4. Use closed ended questions whenever possible
Closed ended survey questions give respondents specific choices (e.g. Yes or No), making it easier to analyze results. Closed ended questions can take the form of yes/no, multiple choice or rating scale. Open ended survey questions allow people to answer a question in their own words. Open–ended questions are great supplemental questions and may provide useful qualitative information and insights. However, for collating and analysis purposes, closed ended questions are preferable.
5. Keep rating scale questions consistent through the survey
Rating scales are a great way to measure and compare sets of variables. If you elect to use rating scales (e.g. from 1 – 5) keep it consistent throughout the survey. Use the same number of points on the scale and make sure meanings of high and low stay consistent throughout the survey. Also, use an odd number in your rating scale to make data analysis easier. Switching your rating scales around will confuse survey takers, which will lead to untrustworthy responses.
6. Logical ordering
Make sure your survey flows in a logical order. Begin with a brief introduction that motivates survey takers to complete the survey (e.g. “Help us improve our service to you. Please answer the following short survey.”). Next, it is a good idea to start from broader–based questions and then move to those narrower in scope. It is usually better to collect demographic data and ask any sensitive questions at the end (unless you are using this information to screen out survey participants). If you are asking for contact information, place that information last.
7. Pre–test your survey
Make sure you pre–test your survey with a few members of your target audience and/or co–workers to find glitches and unexpected question interpretations.
8. Consider your audience when sending survey invitations
Recent statistics show the highest open and click rates take place on Monday, Friday and Sunday. In addition, our research shows that the quality of survey responses does not vary from weekday to weekend. That being said, it is most important to consider your audience. For instance, for employee surveys, you should send during the business week and at a time that is suitable for your business. i.e. if you are a sales driven business avoid sending to employees at month end when they are trying to close business.
9. Consider sending several reminders
While not appropriate for all surveys, sending out reminders to those who haven’t previously responded can often provide a significant boost in response rates.
10. Consider offering an incentive
Depending upon the type of survey and survey audience, offering an incentive is usually very effective at improving response rates. People like the idea of getting something for their time. SurveyMonkey research has shown that incentives typically boost response rates by 50% on average.
One caveat is to keep the incentive appropriate in scope. Overly large incentives can lead to undesirable behavior, for example, people lying about demographics in order to not be screened out from the survey.