Transparency in research is a vital aspect of ensuring the validity and credibility of the findings. A transparent research process means that the research methods, data, and results are openly available to the public and can be easily replicated and verified by other researchers. In this section, we will elaborate on the different aspects that lead to transparency in research.
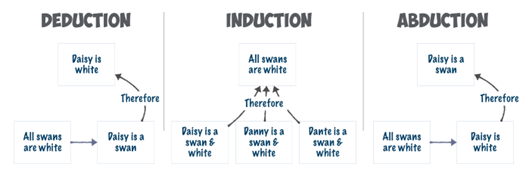
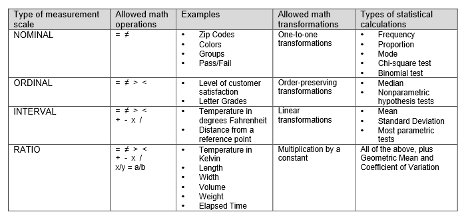
Research Design and Methods: Transparency in research begins with a clear and concise description of the research design and methods used. This includes stating the research question, objectives, and hypothesis, as well as the sampling techniques, data collection methods, and statistical analysis procedures. Researchers should also provide a detailed explanation of any potential limitations or biases in the study, including any sources of error.
Data Availability: One of the critical aspects of transparency in research is data availability. Providing access to the raw data used in the research allows other researchers to verify the findings and conduct further analysis on the data. Data sharing should be done in a secure and ethical manner, following relevant data protection laws and regulations. Open access to data can also facilitate transparency and accountability, promoting public trust in the research process.
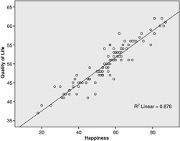
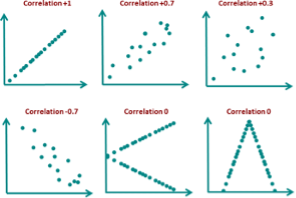
Reporting of Findings: To ensure transparency, researchers should provide a clear and detailed report of their findings. This includes presenting the results in a way that is easy to understand, providing supporting evidence such as graphs, charts, and tables, and explaining any potential confounding variables or alternative explanations for the findings. A transparent reporting of findings also means acknowledging any limitations or weaknesses in the research process.
Conflicts of Interest: Transparency in research also requires that researchers disclose any conflicts of interest that may influence the research process or findings. This includes any funding sources, affiliations, or personal interests that may impact the research. Disclosing conflicts of interest maintains the credibility of the research and prevents any perception of bias.
Open Communication: Finally, researchers should engage in open and transparent communication with other researchers and the public. This includes sharing findings through open access publications and presenting findings at conferences and public events. Researchers should also be open to feedback and criticism, as this can help improve the quality of the research. Open communication also promotes accountability, transparency, and trust in the research process.
In conclusion, transparency in research is essential to ensure the validity and credibility of the findings. To achieve transparency, researchers should provide a clear description of the research design and methods, make data openly available, provide a detailed report of findings, disclose any conflicts of interest, and engage in open communication with others. Following these practices enhances the quality and impact of the research, promoting public trust in the research process.
Examples
- Research Design and Methods: Example: A study on the impact of a new teaching method on student performance clearly states the research question, objectives, and hypothesis, as well as the sampling techniques, data collection methods, and statistical analysis procedures used. The researchers also explain any potential limitations or biases in the study, such as the limited sample size or potential confounding variables.
- Data Availability: Example: A study on the effects of a new drug on a particular disease makes the raw data available to other researchers, including any code used to clean and analyze the data. The data is shared in a secure and ethical manner, following relevant data protection laws and regulations, and can be accessed through an online data repository.
- Reporting of Findings: Example: A study on the relationship between social media use and mental health provides a clear and detailed report of the findings, presenting the results in a way that is easy to understand and providing supporting evidence such as graphs and tables. The researchers also explain any potential confounding variables or alternative explanations for the findings and acknowledge any limitations or weaknesses in the research process.
- Conflicts of Interest: Example: A study on the safety of a new vaccine discloses that the research was funded by the vaccine manufacturer. The researchers acknowledge the potential for bias and take steps to ensure the validity and credibility of the findings, such as involving independent reviewers in the research process.
- Open Communication: Example: A study on the effectiveness of a new cancer treatment presents the findings at a public conference, engaging in open and transparent communication with other researchers and the public. The researchers are open to feedback and criticism, responding to questions and concerns from the audience and taking steps to address any limitations or weaknesses in the research process. The findings are also published in an open access journal, promoting transparency and accountability.